
Comme nous l’avons vu dans l’article précédent part 1 et part 2 le traitement du langage naturel offre des capacités intéressantes qui changent de nombreuses industries aujourd’hui.
Vous êtes-vous déjà demandé comment Spotify Discover Weekly peut vous proposer chaque semaine une sélection personnalisée qui correspond à vos goûts ? Avez-vous déjà cherché une vidéo, et vous trouvez exactement ce que vous cherchez dans votre liste de suggestions sur YouTube ?
N’est-il pas impressionnant de voir comment votre site d’actualités préféré vous sélectionne exactement les articles qui vous intéressent le plus. Dans cet article, nous allons découvrir comment fonctionne le système de recommandation d’article connecté.
Système de recommandation
Un moteur de recommandation est un système qui vise à prédire les préférences de l’utilisateur afin de lui fournir le meilleur UX (la meilleure expérience utilisateur).
Nous pouvons distinguer 3 types de systèmes de recommandation :
1.Filtrage collaboratif
Méthodes basées sur la collecte et l’analyse d’une grande quantité d’informations sur les comportements, les activités ou les préférences des utilisateurs, afin de prédire ce que les utilisateurs aimeront en fonction de leur similarité avec d’autres utilisateurs. Un avantage clé de l’approche collaborative de filtrage est que celle-ci ne repose pas sur le contenu analysable par machine et qu’elle est donc capable de recommander avec précision des éléments complexes tels que les films sans exiger une « compréhension » de l’élément lui-même.
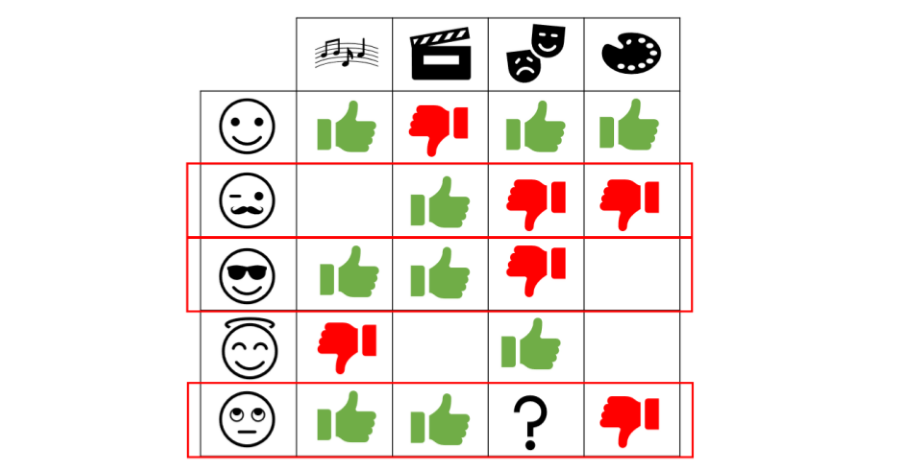
L’exemple ci-dessus explique facilement comment fonctionne le filtrage collaboratif, et en particulier le filtrage collaboratif axé sur l’utilisateur. Imaginez que quelqu’un aime le cinéma et la musique mais déteste la peinture, donc si moi-même j’aime le cinéma et la peinture, j’aimerais probablement aussi la musique. De cette façon, le système de recommandation utilise cette logique pour construire des suggestions basées sur notre similarité.
2.Filtrage fondé sur le contenu
Méthodes basées sur une description de l’élément lui-même et les préférences de l’utilisateur.
Dans un système de recommandation basé sur le contenu, des mots clés sont utilisés pour décrire des éléments ; et l’utilisateur peut également indiquer lui-même ce qui l’intéresse.
3.Système de recommandation hybride
Comme son nom l’indique, ce type de système de recommandation est une combinaison des deux : filtrage collaboratif et filtrage basé sur le contenu. Il est essentiellement utilisé pour surmonter certains des problèmes communs dans les systèmes de recommandation tel que le démarrage à froid : « il s’agit des cas où le système n’est pas en mesure de faire des déductions pour des utilisateurs ou des éléments sur lesquels il n’a pas encore recueilli suffisamment d’informations ».
En ce qui concerne le système de recommandation d’article, nous pouvons utiliser n’importe lequel de ces 3 types.
Aujourd’hui, nous allons voir comment nous pouvons utiliser le traitement du langage naturel pour construire un système de recommandation de filtrage basé sur le contenu. Commençons maintenant !
Allocation de Dirichlet Latente :

L’une des techniques les plus utilisées dans le traitement du langage naturel est la modélisation thématique. C’est un modèle statistique, purement basé sur un apprentissage non supervisé, capable de détecter divers sujets qui apparaissent dans une collection de documents.
En 2003, David Blei, professeur au département de statistiques et d’informatique de l’Université Columbia, a développé avec ses collègues un algorithme puissant appelé « Latent-Dirichlet Allocation ». Depuis, il est devenu l’algorithme principal de nombreux domaines d’application, tels que : modélisation des sujets, classification des documents, regroupement d’images, analyse des sentiments, …
Mais comment ça marche ?
Latent Dirichlet Allocation est considéré comme un « modèle probabiliste avec un processus génératif ». L’idée qui sous-tend le modèle LDA semble simple ; elle suppose qu’un ensemble précis de sujets est décrit à l’avance. Ensuite, les seules caractéristiques observables dont le modèle tient compte sont les mots qui apparaissent dans les documents. Chacun de ces mots présente une certaine probabilité d’appartenir à un sujet spécifique.
Après différentes itérations, le modèle finit par assigner à chaque sujet une collection de mots. En conséquence, chaque document représente un mélange de sujets avec diverses probabilités. Par conséquent, suivant la fréquence d’apparition de ces mots dans chaque document, il attribue à chaque document le sujet avec la plus grande probabilité.
Ci-dessous vous trouverez un diagramme d’un modèle LDA
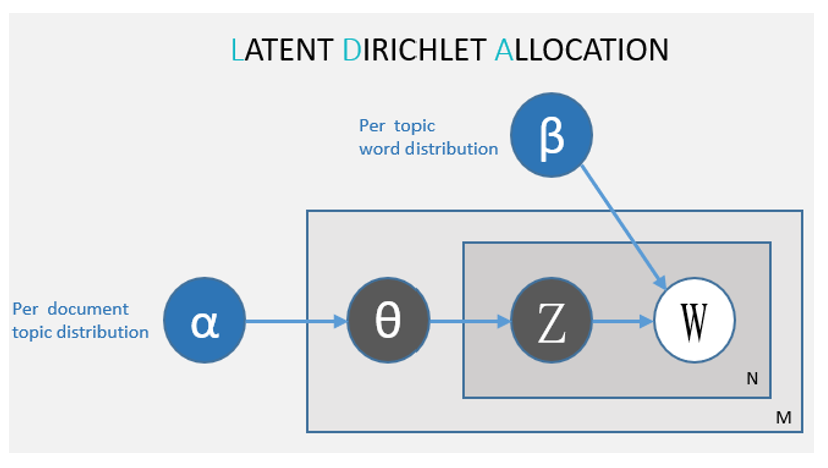
Où :
• α : distribution des sujets par document
• β : distribution de mots par sujet
• θ : Distribution de sujets spécifiques au document
• Z : affectation au sujet
• W : mot observé
Dans le diagramme ci-dessus, nous mettons le mot (W) en blanc parce que c’est la seule caractéristique observée par le modèle, tout le reste est considéré comme une variable latente.
Dans le processus d’optimisation de notre modèle, nous pouvons jouer avec ces paramètres pour obtenir de meilleurs résultats.
Prenons par exemple α et β :
α : l’alpha représente la densité document-thème. Plus un alpha est élevé, plus les documents contiendront de sujets. A l’inverse, plus un alpha est faible, moins les documents contiendront de sujets. En d’autres termes, plus un alpha est élevé, plus les documents semblent être similaires
β : La version bêta représente la densité du mot-sujet. Avec un bêta élevé, les sujets sont composés de la plupart des mots du corpus, et avec un bêta faible, ils se composent de quelques mots seulement. En d’autres termes, plus un bêta est élevé, plus les sujets semblent être similaires.
Donc, si vous utilisez le modèle LDA dans le traitement du langage naturel, c’est à vous de jouer avec ces paramètres. Sinon, vous pouvez simplement utiliser une bibliothèque Python qui fera le travail pour vous .. génial non ?
Mesdames et messieurs, permettez-moi de vous présenter Gensim, une bibliothèque open-source pour la modélisation de sujets non supervisés et le traitement du langage naturel. Cette bibliothèque vous fournit une implémentation rapide du modèle LDA, encore mieux, elle pourrait permettre au modèle d’apprendre les valeurs alpha et bêta pour vous.
Vous voulez voir comment cela fonctionne ? Continuez à lire…
Articles d’Expertime : Modélisation thématique
Je travaille actuellement chez Expertime, une entreprise en pleine croissance spécialisée dans l’innovation et le conseil de solutions basées sur Azure et Office 365 telles que Devops, Data & Artificial Intelligence.
Sur notre site Web, nous avons un blog où nos experts publient des articles sur les nouvelles technologies. J’ai pensé qu’il serait intéressant d’appliquer un modèle de sujet pour comprendre les différents sujets dont mes collègues parlent. Je ne les espionne pas. Je suis simplement curieux.
Je suis allé sur https://www.expertime.com/blog/c/news-tech/ et j’ai sélectionné seulement 3 articles pour rendre cette démo facile.
En fait, j’ai fait quelques recherches sur le Web pour obtenir les données. Pour ce faire, j’ai utilisé quelques bibliothèques qui sont des requêtes et Beautifulsoup.
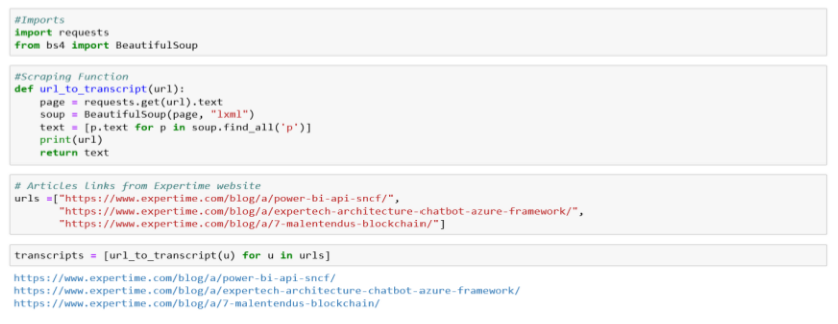
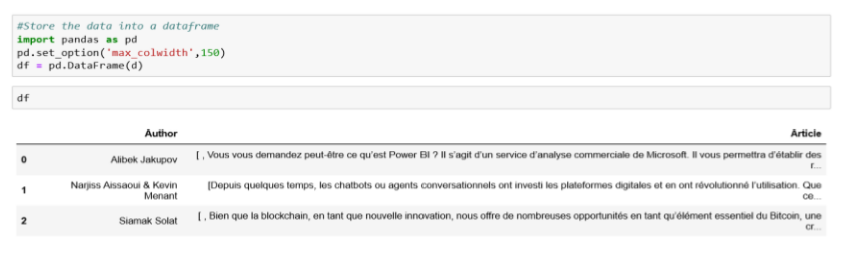
Maintenant, nous devons tout mettre dans une base de données, qui est essentiellement une structure de données étiquetées en deux dimensions, comme ci-dessous :
Une fois que nous avons terminé, nous appliquons certaines des techniques de prétraitement de texte que nous avons apprises dans l’article précédent traitement du langage naturel part 1 et part 2.
- Mettre le texte en minuscules
- Développer les contractions
- Supprimer la ponctuation
- Corriger l’orthographe
- Supprimer les mots d’arrêt
- Partie du filtrage de la parole
De cette façon, nous nous retrouverons avec une base de données propre comme celle-ci :

Dans l’article précédent, nous avons également parlé de la différence entre les données structurées et non structurées, et du fait que le traitement du langage naturel nous fournit le processus permettant d’obtenir des renseignements utiles à partir de textes en appliquant une variété d’algorithmes.
Alors, convertissons notre texte (données non structurées) en une forme plus structurée. C’est pourquoi nous allons utiliser une matrice de durée de document, où chaque ligne est un document (article dans notre cas), et chaque colonne est un terme. Pour ce faire, nous allons utiliser Countvectorizer de Sklearn.
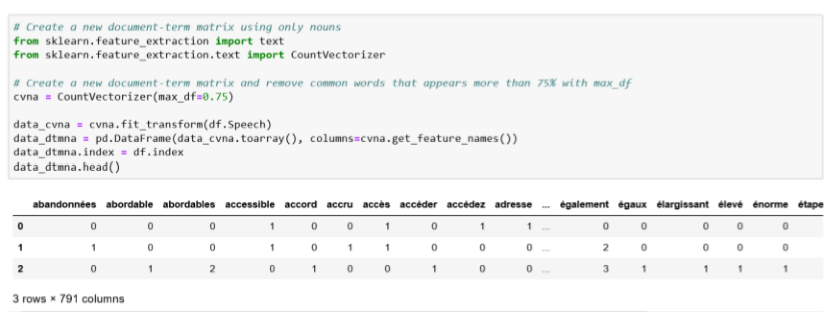
Maintenant que nous avons converti notre texte en matrice, il devient beaucoup plus facile d’appliquer quelques algorithmes mathématiques. Faisons-le! Il est temps de mettre en place le modèle LDA en utilisant Genism.
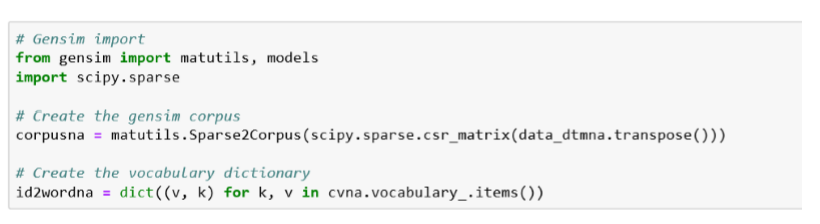
Encore une ligne de code pour appliquer le modèle LDA et c’est fini. Comme vous le voyez ci-dessous, tout ce que nous devons faire est de choisir le nombre de sujets, le nombre de mots décrivant chaque sujet et le nombre de passages ou le nombre d’itérations des algorithmes. C’est littéralement aussi simple que cela. Bien plus tard, vous pourrez jouer avec les paramètres alpha et bêta ou tout simplement laisser Gensim faire le travail pour vous.

Les articles sélectionnés :
– Comment associer Power BI à l’API SNCF ? Quels en sont les intérêts ? https://www.expertime.com/blog/a/power-bi-api-sncf/
– Architecture Chatbot avec Microsoft Azure et Bot Framework https://www.expertime.com/blog/a/expertech-architecture-chatbot-azure-framework/
– 7 malentendus courants au sujet de la Blockchain https://www.expertime.com/blog/a/7-malentendus-blockchain/
Les résultats sont vraiment impressionnants ! Je vais vous laisser juger par vous-même !

Ecrit par Sofiene AZABOU.