
La question du green NLP

Comme vous l’avez peut-être remarqué, les modèles NLP deviennent de plus en plus sophistiqués et se rapprochent de la performance humaine. Cela est dû à des percées scientifiques, à des algorithmes plus optimisés en termes de mémoire, mais aussi à du matériel plus puissant.
L’entraînement de ces modèles entraîne une forte consommation d’énergie, et cette énergie n’est pas toujours dérivée de sources neutres en carbone. Il en résulte une augmentation des émissions de CO2 et un coût de calcul important.
Quelle efficacité et qualité pour les modèles NLP ?
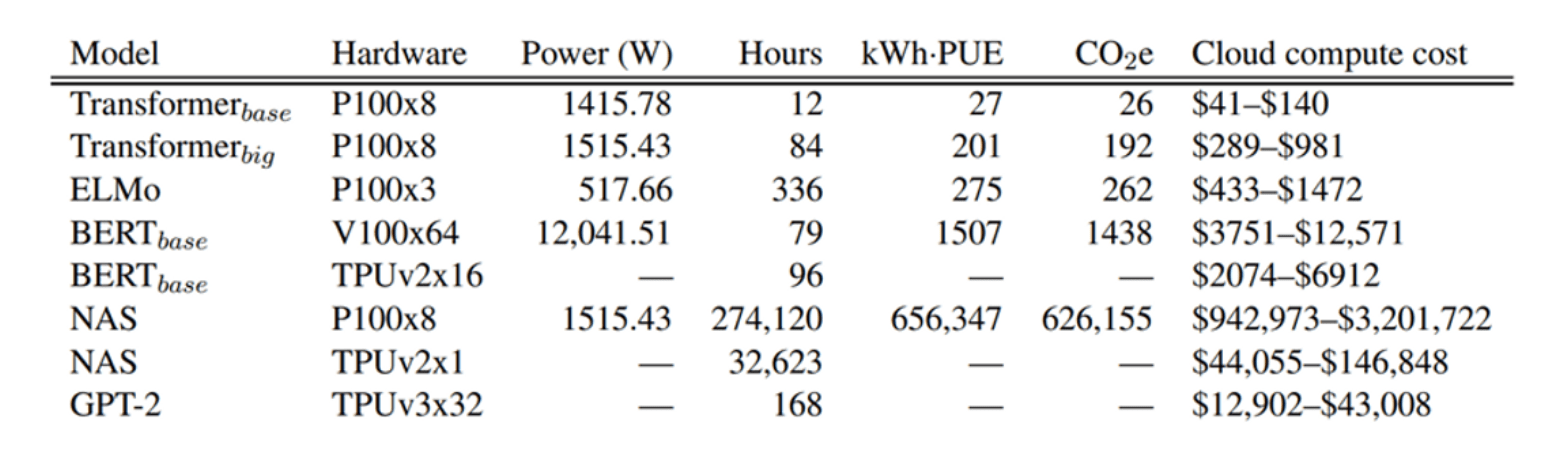
Une étude intéressante sur l’effet environnemental de l’exécution de pipelines NLP en termes d’émissions de CO2 et de coût estimé a été menée par Strubell et al à l’Université du Massachusetts. Pour ce faire, ils ont estimé les kilowatts d’énergie nécessaires pour former une variété de modèles NLP de pointe, puis ont converti cette valeur en émissions de carbone et en coûts d’électricité approximatifs.
Comme on peut le voir dans le tableau, plus le modèle a de paramètres, plus il exige un coût de calcul élevé. Naturellement, on pourrait suggérer d’arrêter d’augmenter la complexité des modèles NLP car les dommages causés à l’environnement sont plus importants que l’impact positif d’un meilleur modèle linguistique. Mais étudions d’abord cette question de différents points de vue avant de tirer des conclusions hâtives.
Un accès équitable aux modèles NLP pour tous
L’exécution de modèles complexes n’est pas à la portée de tous les chercheurs en raison de leur coût élevé et de leurs exigences techniques spécifiques. Cela favorise l’inégalité entre les laboratoires, car ceux qui disposent d’un meilleur financement auront plus de chances d’obtenir un meilleur résultat.
Pour éviter le cycle problématique « les riches deviennent plus riches », il existe de nombreuses initiatives, par exemple Microsoft for startups. Il s’agit d’un programme qui aide les startups à se développer, à créer et à étendre leur réseau en les soutenant dans une approche de partenariat technique et commercial, avec l’aide de crédits Azure gratuits. Ainsi, les ingénieurs peuvent construire, exécuter et gérer des applications sur plusieurs clouds avec les outils et les frameworks de leur choix.
En outre, dans le cas où l’on s’appuie sur une infrastructure cloud, il peut être utile d’appliquer des cadres de développement respectueux de l’environnement, comme Green Ops.
GreenOps est une méthodologie visant à optimiser l’impact écologique des entreprises. Cette pratique donne aux entreprises une méthodologie et des indicateurs pour réduire leur empreinte écologique réalisée par leur consommation de Cloud Computing. L’objectif principal de cette méthodologie est de :
- Concevoir un cadre de bonnes pratiques du cloud pour réduire l’impact écologique des infrastructures cloud tout en respectant les objectifs de transformation des entreprises.
- Développer un outil d’audit pour identifier les actifs du cloud qui nécessitent un changement afin de réduire l’impact de l’infrastructure existante
- Délivrer un éco-score pour encourager l’entreprise dans sa démarche.
Ainsi, la nécessité de créer un cadre est de systématiser la démarche durable en l’intégrant dans les cérémonies de projet.
Cependant, pour les établissements d’enseignement à but non lucratif, s’appuyer sur des services de calcul en cloud tels que AWS, Google Cloud ou Microsoft Azure peut ne pas être une option ou être moins rentable que de construire ses propres centres de calcul. Par conséquent, d’autres approches d’optimisation de l’informatique peuvent être appliquées.
Les mathématiques dites vertes
En tant que scientifique des données, je trouve plus intéressant d’extraire des caractéristiques plus pertinentes et spécifiques à une tâche plutôt que de s’appuyer sur des modèles énormes.
Par exemple, si vous travaillez sur un scénario impliquant un vocabulaire limité, comme les descriptions de produits, les encodeurs One-hot comme Murmurhash V3 peuvent donner des résultats étonnamment bons, alors qu’ils nécessitent beaucoup moins de ressources informatiques.
Un autre exemple est le spam d’opinion trompeur, où les codeurs classiques comme BERT ou ElMo ne fournissent pas les résultats nécessaires en ce qui concerne les avis qui ont été intentionnellement écrits pour sembler authentiques.
Au lieu d’appliquer ces modèles de pointe, les ingénieurs définissent leurs propres caractéristiques, comme le nombre de mots de l’enquête linguistique (LIWC) ou les caractéristiques stylistiques, et obtiennent de meilleurs résultats à un coût de calcul moindre.
Il existe également des techniques de réglage des hyperparamètres, comme la recherche aléatoire ou bayésienne d’hyperparamètres, qui permettent d’améliorer l’efficacité du calcul par rapport à la recherche brute sur grille. Même si le gain en termes de calcul peut sembler insignifiant, à long terme, ces techniques peuvent réduire considérablement la consommation d’énergie.
De ce point de vue, il est important de disposer d’un cadre commun définissant les normes d’intégration d’algorithmes efficaces en termes de calcul dans les bibliothèques ML les plus populaires.
Par exemple, il existe de nombreux paquets mettant en œuvre des techniques de recherche d’hyperparamètres bayésiens, mais les spécialistes des données préfèrent ne pas les appliquer pour régler leurs modèles de TAL en raison de leur incompatibilité avec des bibliothèques populaires telles que PyTorch ou Tensorflow. L’existence d’un tel cadre pourrait améliorer la situation en facilitant l’interopérabilité des paquets.
La NLP pour le bien
On pense que le traitement automatique des langues est surtout utilisé dans le marketing et le commerce en ligne.
C’est partiellement vrai, car la majorité des cas d’utilisation implique l’utilisation de données textuelles pour augmenter les ventes de produits. Cependant, certains projets NLP peuvent améliorer directement l’écologie, comme la prévision de la qualité de l’air à l’aide des médias sociaux (Jiang et al).
Dans cette étude, les chercheurs s’intéressent à la question des mesures de la qualité de l’air, comme la concentration de PM2.5, et aux problèmes de surveillance des changements des conditions de qualité de l’air. Pour résoudre ce problème, ils suggèrent d’exploiter les médias sociaux et le NLP en traitant les utilisateurs comme des capteurs sociaux avec leurs résultats et leurs emplacements. Les résultats de leurs expériences approfondies se sont révélés très prometteurs. En effet, à l’aide du langage naturel, les auteurs ont réussi à surpasser deux méthodes de référence comparatives qui n’utilisaient que des mesures historiques, tandis que leur moteur était capable d’extraire des connaissances essentielles sur la qualité de l’air à partir d’une myriade de tweets dans les médias sociaux.
Ce cas d’usage prouve que l’utilisation des techniques les plus avancées du traitement automatique des langues peut également contribuer à la construction d’un avenir plus durable. Sans aucun doute, l’optimisation des logiciels et du matériel devrait être appliquée chaque fois que cela est possible.
Conclusion
Dans cet article, nous avons brièvement étudié les pipelines NLP les plus populaires du point de vue de l’impact environnemental, de l’efficacité économique et de l’accès équitable.
Après avoir analysé ces aspects, nous pouvons conclure que la première étape serait de créer un cadre commun, comme GreenOps, centralisant toutes les meilleures pratiques d’utilisation de matériel et d’algorithmes efficaces en termes de calcul.
D’énormes fournisseurs de cloud computing comme AWS ou Azure pourraient appliquer ce cadre pour créer des ressources de calcul précieuses, flexibles et respectueuses de l’environnement. Pour les établissements d’enseignement à but non lucratif, l’option la plus appropriée peut être de construire des serveurs centralisés au lieu de s’appuyer sur le cloud computing et de mettre en œuvre des algorithmes respectueux des calculs.
En plus d’être rentable, cette solution permettra également d’offrir un accès équitable à tous les chercheurs, même ceux dont les ressources financières sont limitées, car la capacité du serveur peut être partagée entre de nombreux projets différents.
Enfin, étant donné que le traitement automatique des langues peut contribuer au développement durable de nombreuses façons, comme l’amélioration de la surveillance de la qualité de l’air, il convient d’encourager la poursuite des recherches dans ce domaine.
L’existence d’un ensemble de bonnes pratiques peut également être bénéfique pour les chercheurs individuels, car elle peut faciliter l’intégration de paquets d’optimisation de calcul dans des bibliothèques ML populaires comme Tensorflow et Pytorch. Ainsi, comme nous l’avons vu ci-dessus, grâce à des efforts modestes mais constants, nous pouvons construire un internet plus durable.
Ecrit par Alibek JAKUPOV, Data Scientist & Microsoft MVP Artificial Intelligence @ Expertime