
La nouvelle fonctionnalité de pipelines de déploiement dans Power BI est un outil efficace qui permet aux concepteurs de BI de gérer le cycle de vie du contenu organisationnel au sein de leur entreprise. Grâce à cet outil, vous pourrez développer et tester du contenu Power BI (rapports, tableaux de bord et ensembles de données) avant même qu’ils ne soient consommés par les utilisateurs finaux.
A travers cet article, j’ai essayé de rassembler les étapes les plus essentielles pour implémenter les pipelines Power BI Deployment à partir de la documentation Microsoft, en y ajoutant également une démo.
Crédits : https://docs.microsoft.com/en-us/power-bi/create-reports/deployment-pipelines-overview
Pré requis :
Vous pourrez accéder à la fonction de pipelines de déploiement si les conditions suivantes sont respectées :
-Vous êtes un utilisateur Power BI Pro
-Vous appartenez à une organisation qui a la capacité Premium
-Vous êtes administrateur d’un nouvel espace de travail
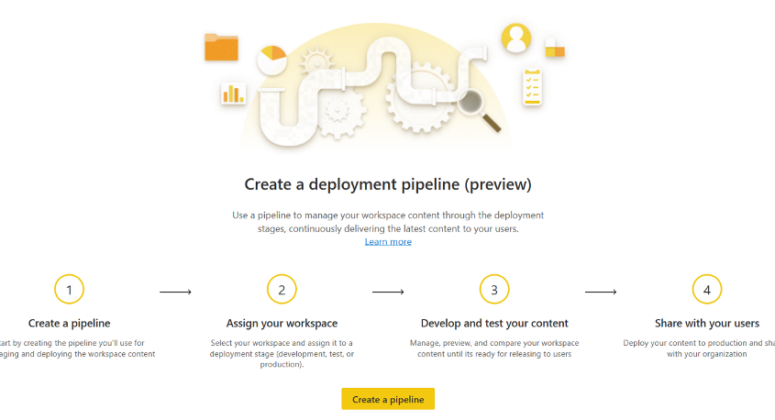
Flux de travail des pipelines de déploiement Power BI
Vous trouverez ci-dessous le flux de travail pour créer un pipeline de déploiement :
- Créer un pipeline
- Attribuer un espace de travail
- Élaborer et mettre à l’essai le contenu
- Partager avec les utilisateurs
- Créer un pipeline
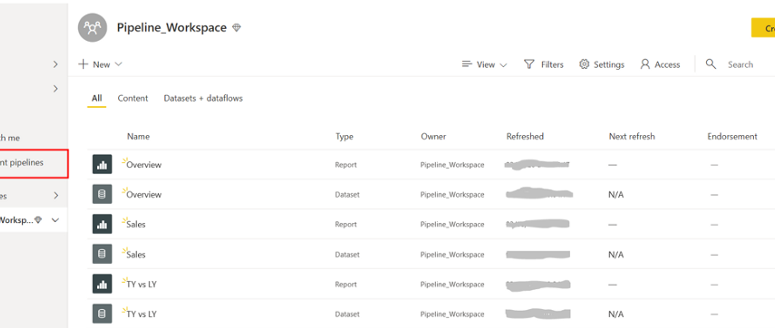
Une fois que vous avez créé votre espace de travail et ajouté votre contenu, sélectionnez Deployment pipelines à gauche dans le navigateur.
Sélectionnez ensuite Créer un pipeline.
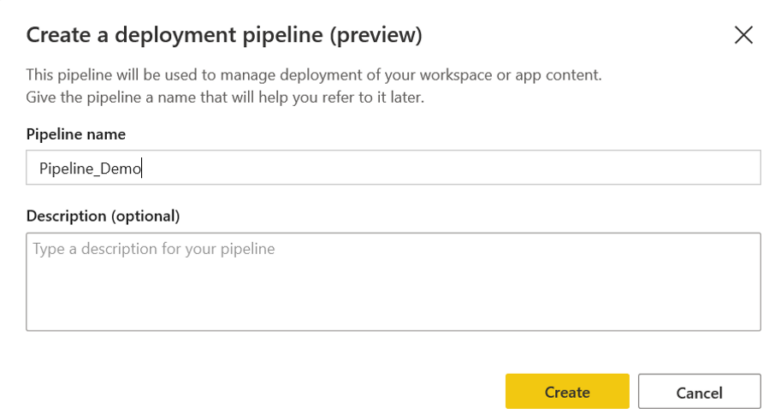
-> Attribuez un nom et une description à votre pipeline
-> Sélectionnez Créer.
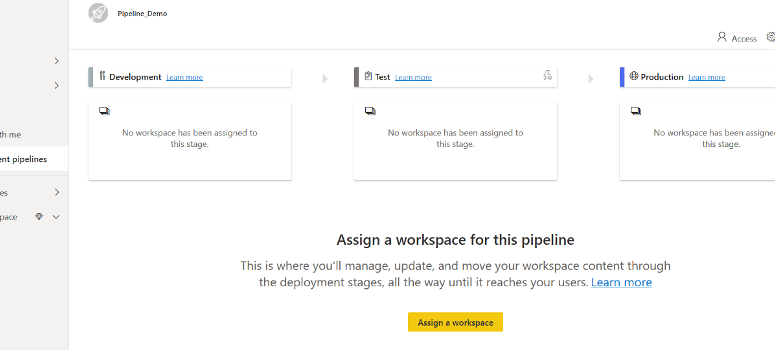
Votre pipeline est maintenant créé. Veuillez noter que vous disposez de trois étapes :
Développement
Cette étape est utilisée pour concevoir, construire et télécharger du nouveau contenu avec d’autres créateurs.Elle constitue la première étape dans les pipelines de déploiement.
Test
À la suite du téléchargement du contenu et à toutes les modifications apportées à l’étape du développement, ce contenu peut être déplacé et passer à l’étape « Test ». Voici trois exemples de ce qui peut être fait dans l’environnement d’essai :
- Partager le contenu avec les testeurs et les réviseurs.
- Charger et exécuter des tests avec des volumes de données plus importants
- Testez votre application pour vous assurer de son rendu et de son bon fonctionnement pour vos utilisateurs finaux
Production
Après avoir testé le contenu, vous pouvez utiliser l’étape de production pour partager la version finale de votre contenu avec les utilisateurs commerciaux à travers l’organisation.
- Attribuer un espace de travail
Après avoir créé un pipeline, vous devez ajouter le contenu que vous souhaitez afin de gérer ce pipeline. L’ajout de contenu au pipeline se fait simplement en attribuant un espace de travail à l’étape du pipeline (vous pouvez d’ailleurs attribuer un espace de travail à n’importe quelle étape).
REMARQUE : Vous ne pouvez attribuer qu’un seul espace de travail à un pipeline de déploiement. Les pipelines de déploiement créeront ensuite des clones du contenu de l’espace de travail, qui seront utilisés aux différentes étapes du pipeline.
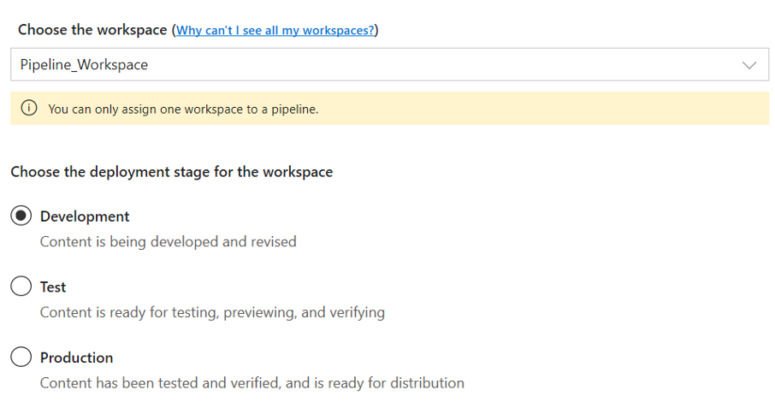
Dans le pipeline de déploiement que vous venez de créer, sélectionnez Assigner un espace de travail.
-> Choisissez un espace de travail dans le menu déroulant
-> Sélectionnez l’étape à laquelle vous souhaitez attribuer cet espace de travail.
Notez que tout le contenu de l’espace de travail a été ajouté lors de l’étape du développement que nous avons mis en place précédemment (avec 3 rapports ainsi que 3 ensembles de données).
- Élaborer et mettre à l’essai le contenu
Déploiement
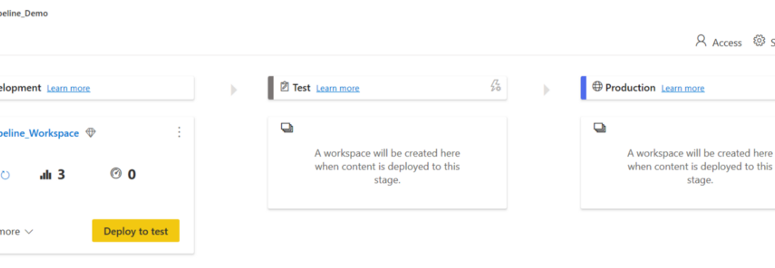
Une fois que nous avons ajouté du contenu à notre étape de développement, nous pouvons aller de l’avant et déployer ce contenu à l’étape suivante, qui est l’étape Test.
Il y a 3 façons de déployer un contenu :
Déployer tout le contenu
Sélectionnez l’étape de déploiement et cliquez sur le bouton de déploiement. Le processus de déploiement crée un espace de travail dupliqué dans l’étape cible. Cet espace de travail comprend tout le contenu existant à l’étape actuelle.
Déploiement sélectif
Pour déployer uniquement des éléments spécifiques, cliquez sur le lien Afficher plus et sélectionnez les éléments que vous souhaitez déployer. Lorsque vous cliquez sur le bouton déployer, seuls les éléments sélectionnés seront déployés à l’étape suivante.
REMARQUE : étant donné que les tableaux de bord, les rapports et les ensembles de données sont liés et ont des dépendances, vous pouvez utiliser le bouton Choisir un sujet lié pour vérifier tous les éléments dont ces éléments dépendent.
Déploiement vers l’arrière
Vous pouvez choisir de déployer à une étape précédente, par exemple dans le cas où vous attribuez un espace de travail existant à une étape de production, puis le déployer à l’envers, d’abord à l’étape de test, puis à celle du développement.
REMARQUE : Le déploiement à une étape précédente ne fonctionne que si l’étape précédente est vide de contenu. Lors du déploiement à l’étape précédente, vous ne pouvez pas sélectionner des éléments spécifiques. Tout le contenu de l’étape sera déployé.
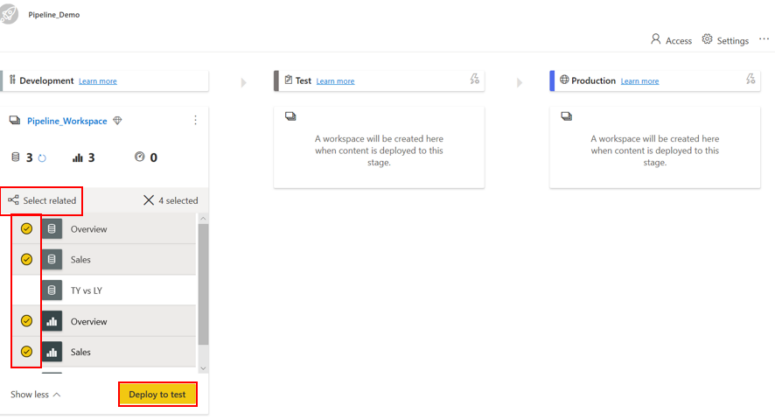
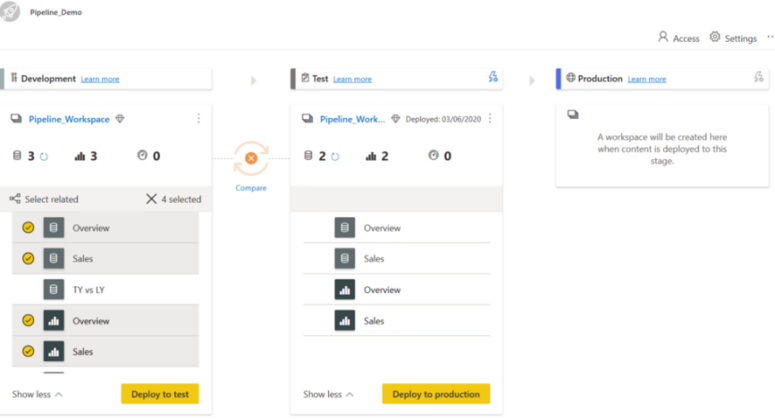
Dans cet exemple, nous avons effectué un déploiement sélectif. Une fois que nous avons choisi le contenu à déployer, nous pouvons cliquer sur Déployer pour le tester.
Notez que le contenu que nous avons sélectionné a été ajouté à l’étape de test.
REMARQUE : Un nouvel espace de travail [Workspace_name][Test] a également été ajouté.
Comparaison des étapes
Maintenant, imaginez que le développeur du rapport a fait quelques changements et le publie à nouveau dans l’espace de travail original, que nous avons attribué à l’étape de test.
Retournez à votre pipeline et cliquez sur le bouton Comparer :
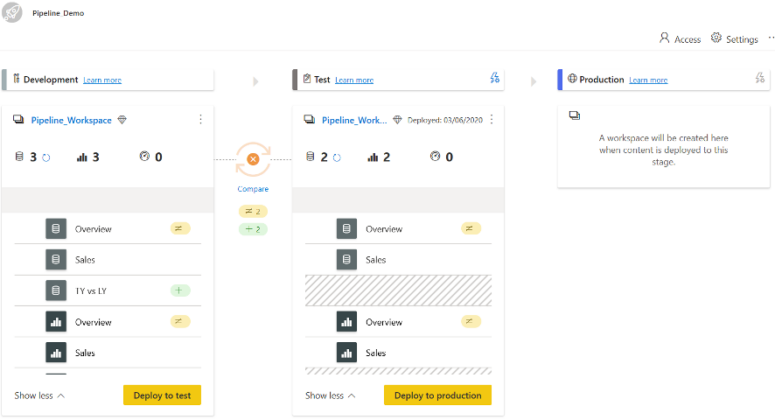
Lorsque deux étapes séquentielles ont du contenu, le contenu est comparé en fonction des métadonnées des éléments de celui-ci.
REMARQUE : Cette comparaison ne comprend pas la comparaison des données ni l’actualisation du temps entre les différentes étapes.
Pour permettre un aperçu visuel rapide des différences entre deux étapes séquentielles, un indicateur d’icône de comparaison apparaît entre elles. L’indicateur de comparaison se lit comme suit :
Indicateur vert : Les métadonnées de chaque élément de contenu aux deux étapes sont les mêmes.
Indicateur orange : Indique si certains éléments de contenu à chaque étape ont été modifiés ou mis à jour (ont des métadonnées différentes), ou s’il y a une différence dans le nombre d’éléments entre les étapes.

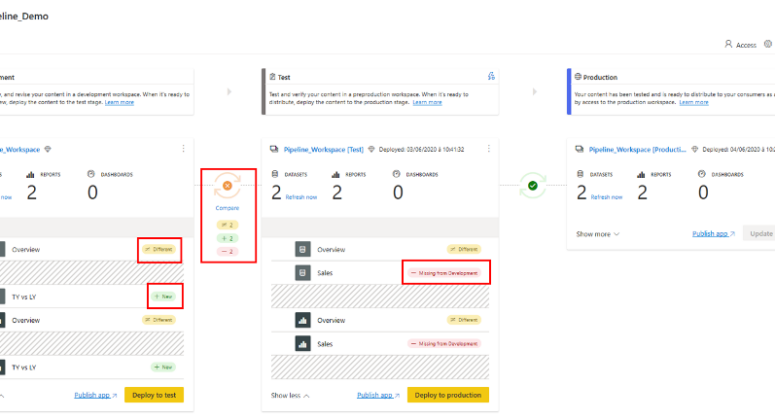
Lorsque deux étapes séquentielles ne sont pas identiques, un lien de comparaison apparaît sous l’icône de comparaison orange. Cliquez sur le lien pour ouvrir la liste des éléments de contenu aux deux étapes de la vue Comparer. La vue de comparaison vous aide à suivre les changements ou les différences notables entre les éléments, à chaque étape du pipeline. Les éléments modifiés reçoivent l’une des étiquettes suivantes :
Nouveau : Un nouvel élément à l’étape source. Il s’agit d’un élément qui n’existe pas à l’étape cible. Après le déploiement, cet élément sera cloné jusqu’à l’étape cible.
Différent : Un élément qui existe à la fois dans l’étape source et dans l’étape cible, si l’une des versions a été modifiée après le dernier déploiement.
REMARQUE : Après le déploiement, l’élément de l’étape source écrasera l’élément de l’étape cible, peu importe où le changement a été apporté.
Manquant : Cette étiquette indique qu’un élément apparaît dans l’étape cible, mais pas dans l’étape source.
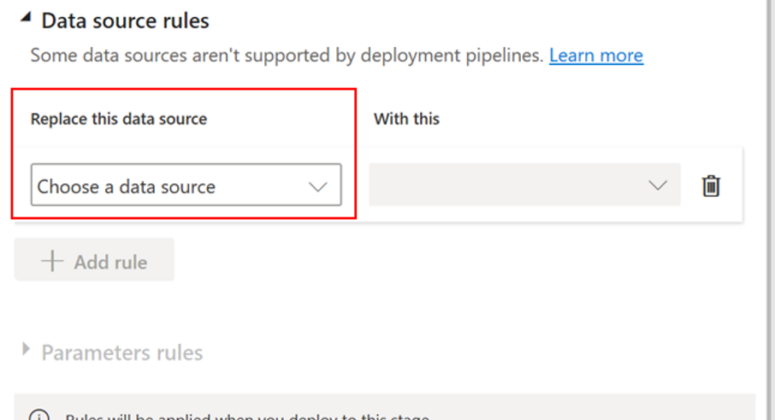
Règles de l’ensemble de données
Les règles d’ensemble de données sont définies sur les sources de données et les paramètres, dans chaque ensemble de données. Ils déterminent les valeurs des sources de données ou des paramètres d’un ensemble de données spécifique. Par exemple, si vous voulez qu’un ensemble de données dans une étape de production pointe vers une base de données de production, vous pouvez définir une règle pour cela. La règle est définie à l’étape de la production, sous l’ensemble de données approprié. Une fois la règle définie, le contenu déployé du test à la production héritera de la valeur définie dans les règles de l’ensemble de données, et s’appliquera toujours ainsi tant que la règle est inchangée et reste valide.

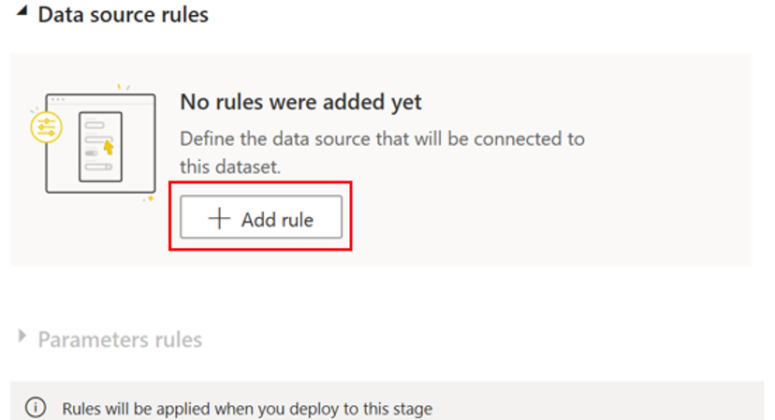
Sélectionnez un ensemble de données dans la liste déroulante et Ajouter une règle.
Choisissez la source de données à remplacer.
Sélectionnez-en une autre
-> Choisissez la nouvelle source de données que vous souhaitez utiliser pour cette étape
-> Enfin, sélectionnez Enregistrer et fermer.
- Partager avec les utilisateurs
Une fois le pipeline créé, vous pouvez le partager avec d’autres utilisateurs ou le supprimer. Lorsque vous partagez un pipeline avec d’autres, les utilisateurs avec qui vous partagez le pipeline auront accès au pipeline. L’accès au pipeline permet aux utilisateurs d’afficher, de partager, de modifier et de supprimer le pipeline.

Ecrit par Sofiene Azabou