
Récemment, j’ai beaucoup parlé d’OpenAI et de GPT à travers diverses intégrations. Mais même si le traitement du langage naturel (NLP) est le domaine le plus important pour les IA génératives, ce n’est pas le seul. Aujourd’hui, je vais parler de Computer Vision à travers le modèle CLIP d’OpenAI et le modèle Florence de Microsoft et leur intégration dans les nouvelles fonctionnalités offertes en avant-première dans Azure Vision.
CLIP
CLIP, développé par OpenAI, est un puissant modèle de réseau neuronal qui signifie « Contrastive Language-Image Pretraining ». Contrairement aux modèles d’IA traditionnels qui reposent sur l’apprentissage supervisé, CLIP est entraîné à l’aide d’un vaste ensemble de données contenant des paires d’images et de textes (400 millions). Il a appris à associer les images et leurs descriptions textuelles correspondantes, ce qui lui permet de comprendre et de générer des représentations significatives d’images et de textes.
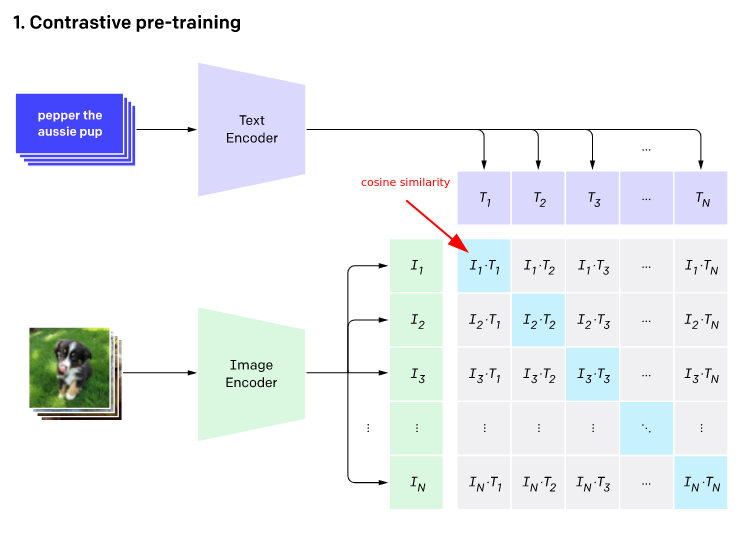
Si vous avez lu mon précédent billet sur la recherche de similarité vectorielle, c’est un peu le même principe. Nous capitalisons sur les propriétés des vecteurs pour trouver du sens entre les textes et les images. Cette approche innovante permet à CLIP d’effectuer un large éventail de tâches, y compris la classification d’images, la génération d’images, et même l’apprentissage à partir de zéro, où il peut reconnaître des objets sans entrainement spécifique sur ces objets.
FLORENCE
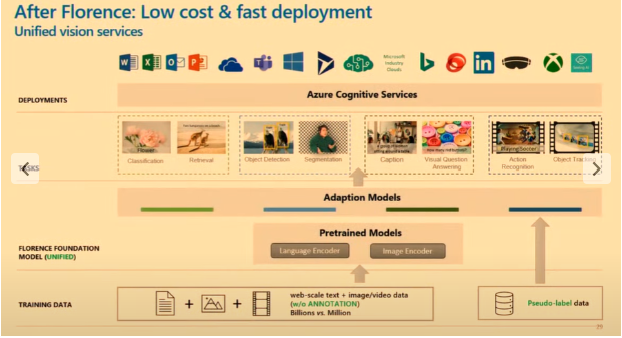
Florence est un modèle de fondation multimodal de Microsoft, entraîné avec des milliards de paires texte-image et intégré dans Azure Cognitive Service for Vision. L’objectif de Florence était de disposer d’un modèle capable de s’adapter à différents types de tâches. Dans leurs articles, ils ont défini 3 dimensions :
- L’espace : de grossier à fin (classification, détection, segmentation).
- Temps : de statique à dynamique (images et vidéos).
- Modalité : du visuel au multi-sens (profondeur, légendes).
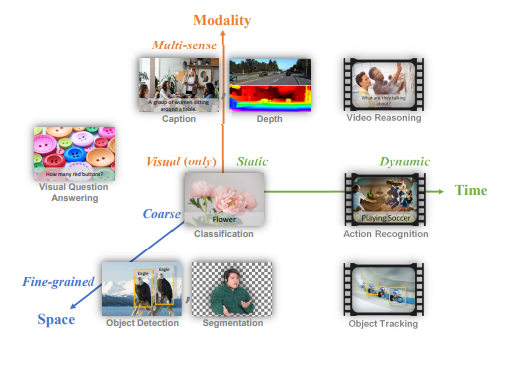
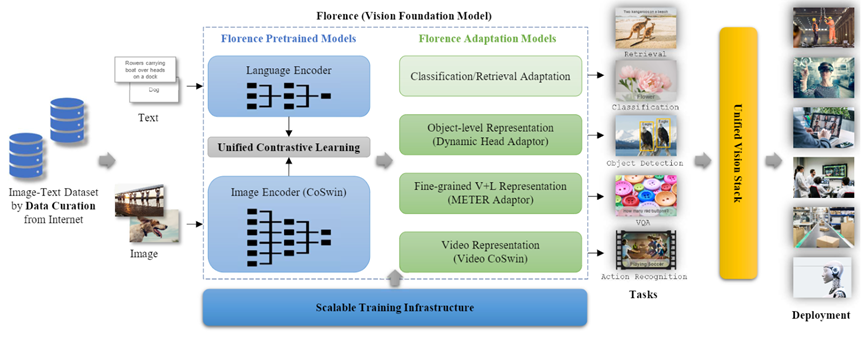
Florence a été pré-entraînée à l’aide d’un vaste ensemble de données d’images et de légendes. L’entraînement a consisté à déterminer quelles images correspondent à quelles légendes (même apprentissage contrastif que celui utilisé dans CLIP). Florence élargit la représentation pour prendre en charge le niveau de l’objet, les modalités multiples et les vidéos respectivement.
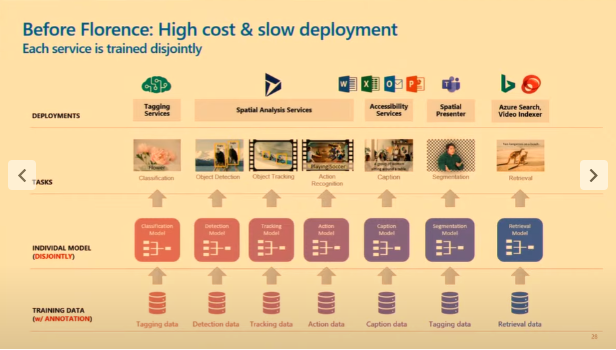
Avant Florence, chaque service était entraîné séparément, ce qui entraînait des coûts élevés et des déploiements lents. Désormais, grâce à ses services de vision unifiée, Florence réduit les coûts et accélère les déploiements.
Actualités Azure Vision
L’intégration de Florence dans Azure Cognitive Services a permis de développer de nouvelles fonctionnalités (en preview).
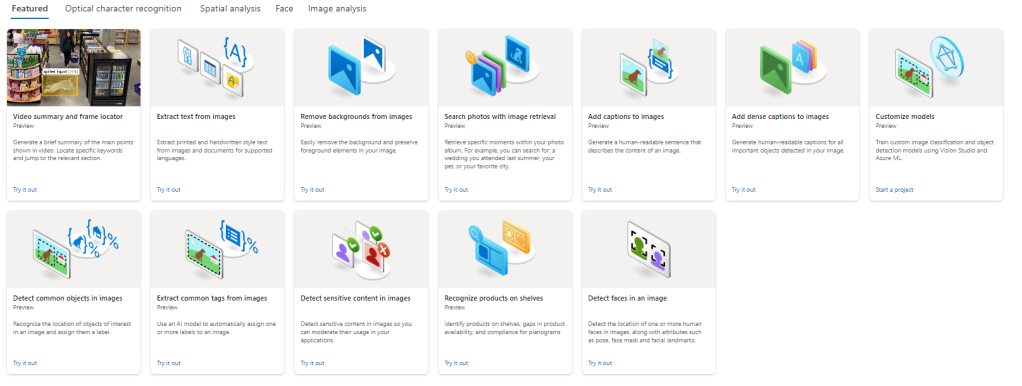
Légendes denses : fournir des légendes riches, des suggestions de conception, un texte alternatif accessible, une optimisation du référencement… La vidéo ci-dessous illustre cette fonctionnalité. Les différentes légendes se chevauchent pour fournir une description détaillée de la scène.
Recherche d’images : améliorer les recommandations de recherche et les publicités avec une requête en langage naturel : demande d’aperçu privé. Le diagramme ci-dessous explique l’utilisation de la similarité vectorielle pour retrouver des images pertinentes. La vidéo montre un exemple sur l’interface Azure Studio.

Suppression de l’arrière-plan : segmentation des personnes et des objets par rapport à leur arrière-plan d’origine.


Personnalisation des modèles : réduction des coûts et des délais pour fournir des modèles personnalisés qui correspondent aux cas d’utilisation de l’entreprise.
Résumé vidéo : recherche et interaction avec le contenu vidéo, localisation du contenu pertinent sans métadonnées supplémentaires : demande de prévisualisation privée.
Les fonctionnalités présentées sont disponibles dans Azure Vision Studio. Vous pouvez les tester par vous-même.
Intégration avec M365 Apps
Dans le but d’intégrer l’IA à ses outils, Microsoft intègre les services Vision dans ses applications M365 (Teams, PowerPoint, Outlook, Word, Designer et OneDrive) et les utilise dans le centre de données Microsoft pour mettre en œuvre des fonctionnalités innovantes, notamment des capacités de segmentation dans Teams pour les réunions virtuelles, le sous-titrage des images pour un texte alternatif automatique dans PowerPoint, Outlook et Word afin d’améliorer l’accessibilité, le marquage et la recherche d’images améliorés dans Designer et OneDrive pour une meilleure gestion des images, et l’exploitation des services Vision dans les centres de données Microsoft pour améliorer la sécurité et la fiabilité de l’infrastructure.
Ecrit par Laurent Gagliardi, Ingénieur Data chez Expertime