

Azure Text Analytics est un service d’IA qui permet de découvrir des informations telles que le sentiment, les entités, les relations et les phrases clés dans un texte non structuré. Il existe une excellente documentation qui fournit un guide étape par étape sur la façon de démarrer avec la bibliothèque client Text Analytics et l’API REST. Cependant, nous avons récemment commencé à nous préoccuper de la question de la parallélisation de l’exécution de ces extraits de code. Ainsi, dans cet article, nous allons voir comment appeler l’API Text Analytics en parallèle. C’est parti !
Conditions préalables
– Abonnement Azure – Créez-en un gratuitement
– Python 3.x
– Une fois que vous avez votre abonnement Azure, créez une ressource Text Analytics dans le portail Azure pour obtenir votre clé et votre point de terminaison. Une fois la ressource déployée, cliquez sur Aller à la ressource.
- Vous aurez besoin de la clé et du point de terminaison de la ressource que vous avez créée pour connecter votre application à l’API Text Analytics. Vous collerez votre clé et votre point de terminaison dans le code ci-dessous plus tard dans le démarrage rapide.
- Vous pouvez utiliser le niveau de tarification gratuit (F0) pour essayer le service, et passer plus tard à un niveau payant pour la production.
– Pour utiliser la fonction d’analyse, vous aurez besoin d’une ressource d’analyse de texte avec le niveau de tarification standard (S).
Pour plus de détails sur les tarifs, merci de vous reporter à la référence officielle.
Important : en créant la ressource, vous avez peut-être remarqué que vous pouviez envoyer jusqu’à 1 000 appels par minute.

Super, mais comment envoyer 1 000 appels par minute ? C’est pourquoi nous devons également créer une ressource databricks. Suivez les étapes énumérées dans cette référence, et passez à l’étape suivante.
Configuration du cluster
Il n’y a rien de spécial dans cette étape, il suffit de configurer le cluster en fonction du niveau de parallélisation que vous souhaitez avoir. Voici la configuration de notre cluster :

Comme vous le voyez, c’est assez simple. Vous pouvez augmenter le nombre de travailleurs, et améliorer chaque travailleur, mais n’oubliez pas le quota d’utilisation.
Assez parlé, codons
Imports
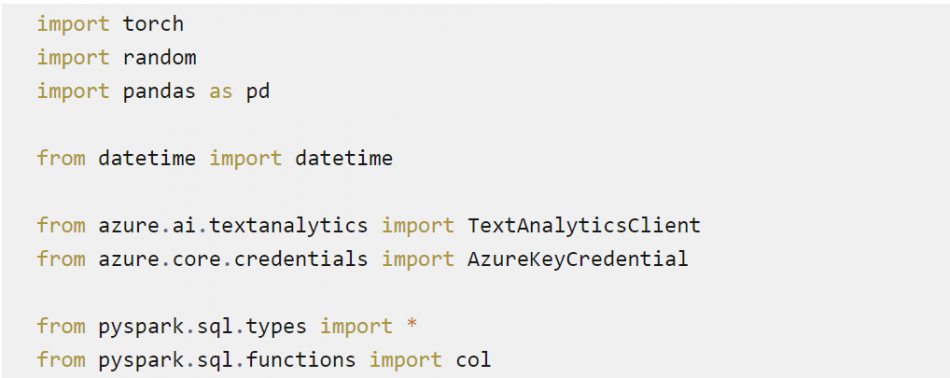
Nous avons importé les types et fonctions de pyspark.sql, afin de paralléliser notre code.
Définissez vos constantes
![]()
Maintenant, nous allons lire les données et les convertir en dataframe spark (nous avons préalablement téléchargé notre fichier csv dans l’espace de travail databricks, bien sûr).
![]()
Ici, nous avons utilisé un jeu de données relativement important de 50 000 proverbes français, que nous allons traiter avec l’API d’analyse de texte.
Maintenant, créez les fonctions d’aide.
Comme vous l’avez remarqué, les fonctions d’aide sont exactement les mêmes que dans la référence officielle.
Créons maintenant une fonction NLP qui appelle l’API d’analyse de texte et récupère les entités nommées de chaque ligne de notre dataframe spark.
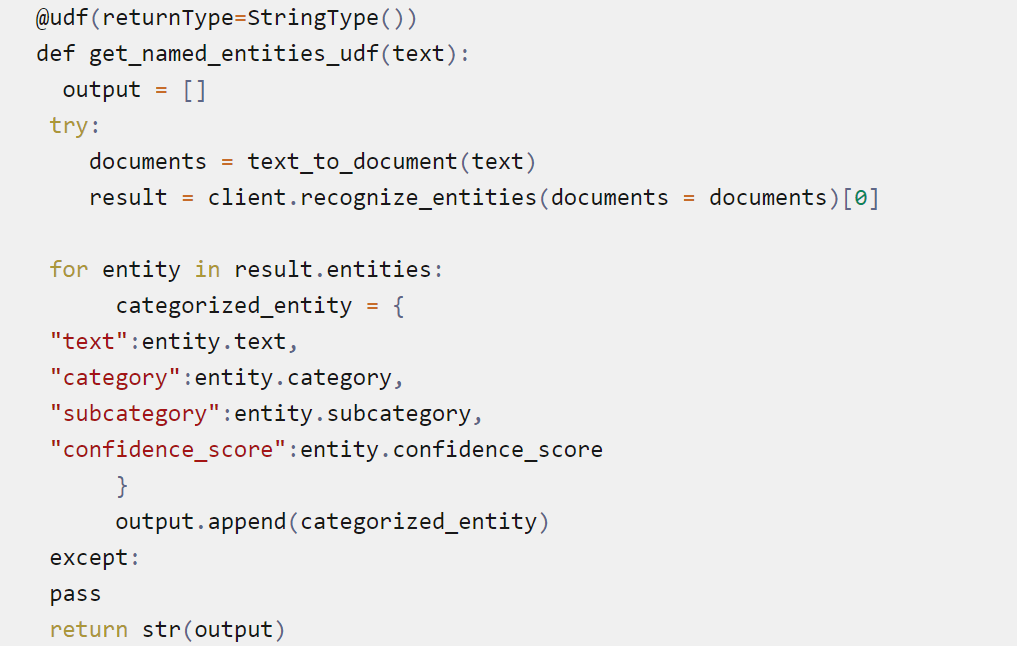
Vous avez peut-être remarqué que nous avons défini notre fonction comme UDF. Ceci est nécessaire pour appliquer cette fonction à toutes les lignes en parallèle.
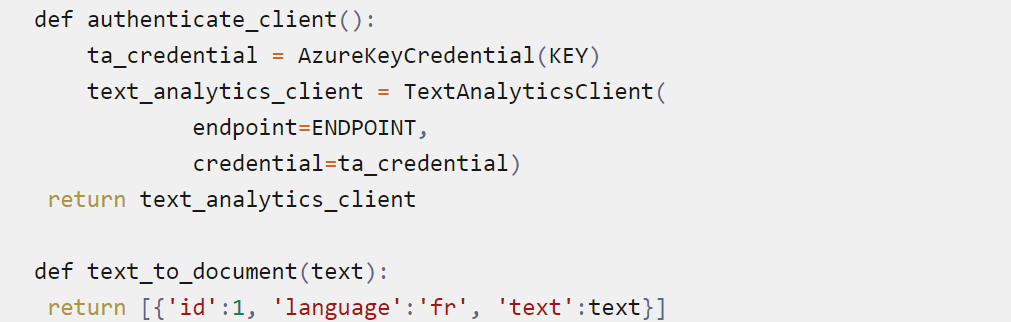
Maintenant vous pouvez authentifier le client.
![]()
Et régler l’heure de début
![]()
Maintenant, nous pouvons exécuter le code en parallèle.
![]()
Important : Nous avons réglé le niveau de répartition à 36 car nous avions 8 nœuds Worker avec 4 cœurs, et un nœud Driver qui est le même que le nœud Worker. 4*9=36.
Ceci lancera l’évaluation ‘paresseuse’ de votre code, donc ajoutez une commande pour exécuter réellement le code et estimer le temps écoulé.

Et n’oubliez pas d’enregistrer vos données en tant qu’un ensemble de données géré.
![]()
Et voilà !
Discussions
L’ensemble de données avec 50 000 lignes a pris environ 40 minutes à exécuter, en comparaison à l’approche classique (en série), qui a pris toute la nuit. Plutôt efficace, non ? Cependant, l’api d’analyse de texte permet d’exécuter le code par lot (10 lignes par requête http), donc théoriquement il peut être exécuté 10 fois plus vite, mais on ne sait toujours pas exactement comment convertir cette fonction en UDF. Rookie va poursuivre ses recherches et vous tiendra au courant.
Ecrit par Alibek JAKUPOV