
Eléments :
- Caméras web/capteurs vidéo
Le moteur doit analyser les signes de la fatigue en temps réel.
Après la première analyse on peut définir le scénario suivant :
Outils :
Custom Vision de Microsoft (entraînement), OpenCV (découpage de la vidéo en frames)
Procédure :
Découpage du flux vidéo en temps réel -> analyse de la ‘frame’ (composant minimal du flux vidéo) -> en fonction du résultat – activation/désactivation du modèle suivant.
Mise en place :
La procédure a été inspirée par la compétition Kaggle
State Farm Distracted Driver Detection : Can computer vision spot distracted drivers?
https://www.kaggle.com/c/state-farm-distracted-driver-detection

Exemple
safe driving
1
texting - right
2
talking on the phone - right
3
texting - left
4
talking on telephone - left
5
operating the radio
6
drinking
7
reaching behind
8
hair and make up
9
talking to passenger
10
Analyse :
Base d’apprentissage : 22 000 images
Nombre d’images par classe : 2 000 images
Nombre de chauffeurs (dans la base d’apprentissage) : 27
Les approches qui ont été utilisées pour résoudre le problème de la conduite sont assez diverses. On a pris un des exemples publics :
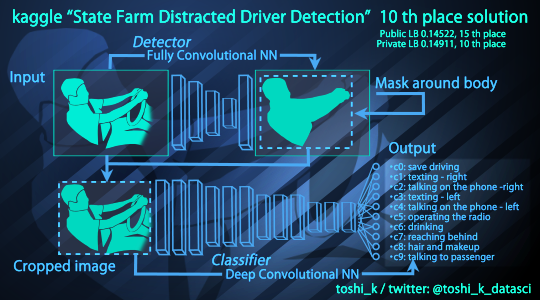
https://github.com/toshi-k/kaggle-distracted-driver-detection
N.B. En utilisant le service de la vision personnalisée il est possible de diminuer la taille de la base d’entraînement. Pour la première version du moteur il est préférable de définir 1 point de prise de vidéo. Pour augmenter la qualité il est également possible de créer 3 points de prise de photos, ce qui implique 3 modèles différents (à voir avec le client si c’est techniquement faisable).

https://i.ytimg.com/vi/p6Yu8w7aVYQ/maxresdefault.jpg
{kind=link}
Les approches possibles :
Famille VGG :
- VGG-16
- VGG-19
Famille ResNet
- ResNet-50
- ResNet-101
- ResNet-152
Famille Inception.
De plus, il est théoriquement possible d’utiliser SegNet :

https://habr.com/ru/post/307078/.
P.S. On a également testé API Vidéo Indexer de Microsoft. Après l’analyse le résultat est :
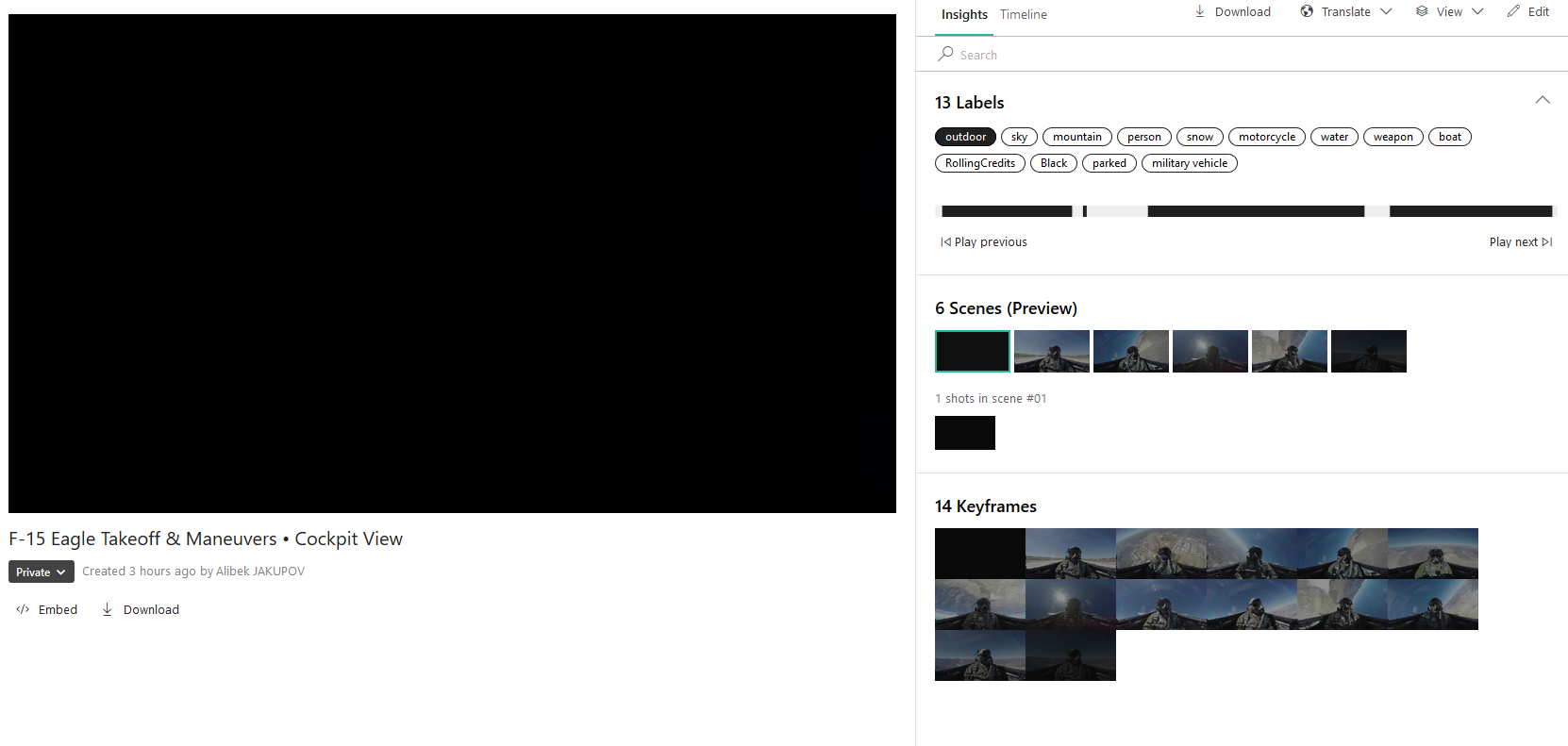
Vidéo :
Il peut être pratique d’utiliser l’API pour décomposer la vidéo en scènes au lieu d’analyser les cadres.
Ecrit par, Alibek JAKUPOV